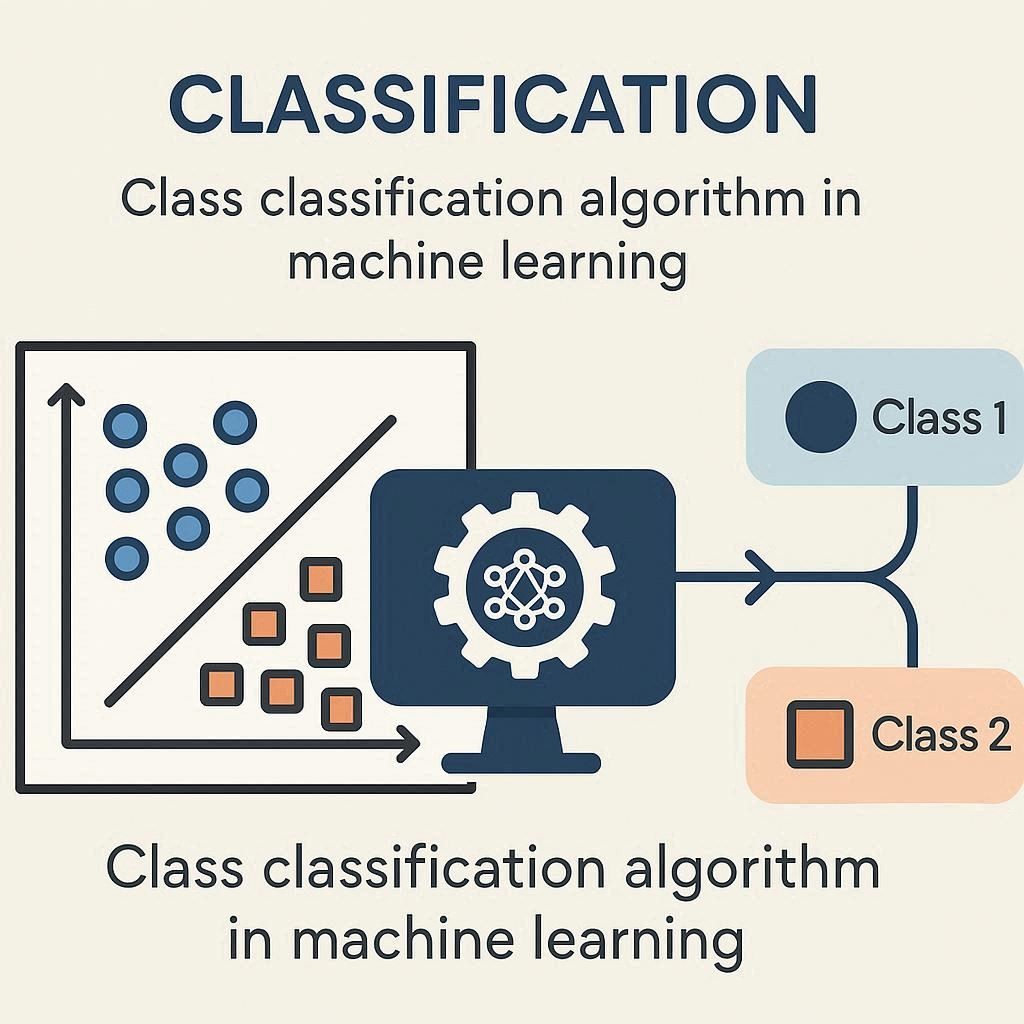
What is class classification algorithm in machine learning?
In machine learning, a classification algorithm (sometimes called a "class classification algorithm") is a type of supervised learning algorithm used to categorize input data into predefined classes (or categories).
Think of it as teaching a computer to answer questions like:
"Is this email spam or not spam?"
"Does this image contain a cat, dog, or bird?"
"Will this loan applicant default or not?"
How It Works
Training Data: The algorithm is fed labeled data (inputs with known outputs). For example, a dataset of emails labeled as spam or not spam.
Model Learning: The algorithm learns patterns and relationships between the input features (like words in an email) and the output labels (spam or not).
Prediction: Once trained, the model can predict the class of new, unseen data.
Evaluation: The model is tested with separate data to measure accuracy, precision, recall, and other metrics.
Common Classification Algorithms
Logistic Regression – despite the name, it’s for binary classification (e.g., yes/no).
Decision Trees – split data into branches based on feature values.
Random Forests – an ensemble of decision trees for better accuracy.
Support Vector Machines (SVM) – find the best boundary (hyperplane) between classes.
Naïve Bayes – based on probability and Bayes’ theorem, often used in text classification.
k-Nearest Neighbors (k-NN) – classifies a new point based on the majority label of its nearest neighbors.
Neural Networks / Deep Learning – powerful models for complex tasks like image recognition or natural language processing.
Types of Classification
Binary Classification: Two classes (e.g., spam vs. not spam).
Multiclass Classification: More than two classes (e.g., dog vs. cat vs. rabbit).
Multilabel Classification: Each instance can belong to multiple classes at once (e.g., a movie can be comedy and romance).
In summary:
A classification algorithm in machine learning is a method used to automatically categorize data into classes based on learned patterns from labeled training data.
Example: Spam Email Detection
1. Collect Data (Training Data)
We start with emails labeled as spam or not spam:
Email A:
"Win a free iPhone now!!!"→ SpamEmail B:
"Meeting scheduled at 10 AM"→ Not SpamEmail C:
"Lowest price for medicines, click here"→ SpamEmail D:
"Your invoice is attached"→ Not Spam
2. Feature Extraction
We convert email text into features (numbers the algorithm can use).
For example:
Contains word “free”
Number of exclamation marks
Contains phrase “click here”
Email length
So, "Win a free iPhone now!!!" might become:[free=1, exclamations=3, click_here=0, length=5]
3. Train the Model
We feed these features and labels into a classification algorithm (e.g., Naïve Bayes).
The model learns patterns:
If an email contains “free,” it’s more likely spam.
If it contains “invoice,” it’s more likely not spam.
4. Make Predictions
New email: "Get FREE gift card now!!!"
Converted into features:[free=1, exclamations=3, click_here=0, length=4]
Model predicts → Spam.
5. Evaluate the Model
We test it with unseen data (say 100 emails):
90 classified correctly
10 misclassified
Accuracy = 90%.
Summary:
A classification algorithm takes labeled training data, learns the patterns, and then predicts the correct class for new, unseen data.
Understanding Class Classification Algorithms in Machine Learning
Class classification algorithms are a fundamental part of machine learning, designed to categorize data into predefined groups or classes. For example, they can help determine whether an email is spam or not, whether a tumor is malignant or benign, or whether a customer is likely to buy a product. The primary goal is to create a model that can generalize patterns from historical data and make accurate predictions on new, unseen data.
Common Types of Classification Algorithms
There are several widely used classification algorithms, each with unique strengths and suitable use cases:
Logistic Regression – A statistical method that models the probability of a binary outcome.
Decision Trees – A tree-like structure that splits data based on feature values, making them easy to interpret.
Random Forest – An ensemble method that combines multiple decision trees to improve accuracy and reduce overfitting.
Support Vector Machines (SVMs) – Powerful for high-dimensional data, they aim to find the best boundary (hyperplane) between classes.
Naïve Bayes – A probabilistic model based on Bayes’ theorem, often used for text classification like spam filtering.
K-Nearest Neighbors (KNN) – A simple approach that classifies based on the majority label of the nearest data points.
Neural Networks – Inspired by the human brain, these models are highly flexible and suitable for complex tasks like image recognition.
How to Train a Classifier Model
Training a classification model involves several key steps:
Data Collection – Gather relevant data that represents the problem domain.
Data Preprocessing – Clean the data by handling missing values, normalizing features, and encoding categorical variables.
Splitting Data – Divide the dataset into training and testing sets (commonly 80/20).
Model Selection – Choose an appropriate classification algorithm based on the nature of the problem.
Training – Feed the training data into the model so it can learn patterns and relationships.
Hyperparameter Tuning – Adjust algorithm parameters (e.g., learning rate, tree depth) to improve performance.
Testing – Evaluate the trained model using the testing dataset to check how well it generalizes.
Evaluating the Accuracy of Classification Models
Accuracy alone may not always reflect the real performance of a classification model. Therefore, multiple metrics are used:
Accuracy – The ratio of correct predictions to total predictions.
Precision – The proportion of true positive predictions out of all predicted positives.
Recall (Sensitivity) – The proportion of true positives correctly identified out of all actual positives.
F1-Score – A harmonic mean of precision and recall, useful when dealing with imbalanced datasets.
Confusion Matrix – A table that provides insights into the distribution of correct and incorrect predictions.
ROC Curve & AUC Score – Graphical tools to evaluate model performance across different thresholds.
Practical Applications of Classification Algorithms
Classification algorithms are widely applied across industries:
Healthcare – Diagnosing diseases, predicting patient outcomes, and classifying medical images.
Finance – Detecting fraudulent transactions and assessing credit risk.
Marketing – Customer segmentation, churn prediction, and targeted advertising.
Technology – Spam detection, sentiment analysis, and speech recognition.
Security – Intrusion detection and facial recognition systems.